When is a cluster not a cluster? Read on to learn about PostgreSQL clusters.
You keep using that word..
PostgreSQL uses the term cluster to refer to a “cluster” of databases, as opposed to the usual notion of a group of servers or VMs working in a co-ordinated fashion. As the venerated manual says in Chapter 2:
… a collection of databases managed by a single PostgreSQL server instance constitutes a database cluster.
In practice, a cluster consists of two things:
- A directory, called the data directory, having a set of files created and managed by Postgres tools and processes. These files contain databases, tables and all other logical entities that you interact with.
- A master process, called postgres, which when running manages the files in this directory and provides interfaces to manipulate the contents.
As it turns out, using clusters can be quite useful in certain situations – like creating test fixtures for automated tests, bringing up a temporary database without disturbing any existing Postgres setup, running different versions of Postgres at the same time etc.
The data directory
All the data for a cluster – including even it’s configuration – can be completely contained inside the data directory. When you create a data directory using postgres tools, it is self-contained to start with. Stopping the postgres process and taking a copy of this directory serves as a complete backup of the data for the cluster. The entire directory can be relocated elsewhere and continue to work just fine.
It does not have to be self-contained, though. When you install Postgres
through your Linux distro’s package manager, it sets up things a bit differently
to conform to common practices, like having the logs under /var/log and
configuration under /etc. You might also set up
tablespaces
that will place data outside the data directory.
Creating a cluster data directory is pretty easy:
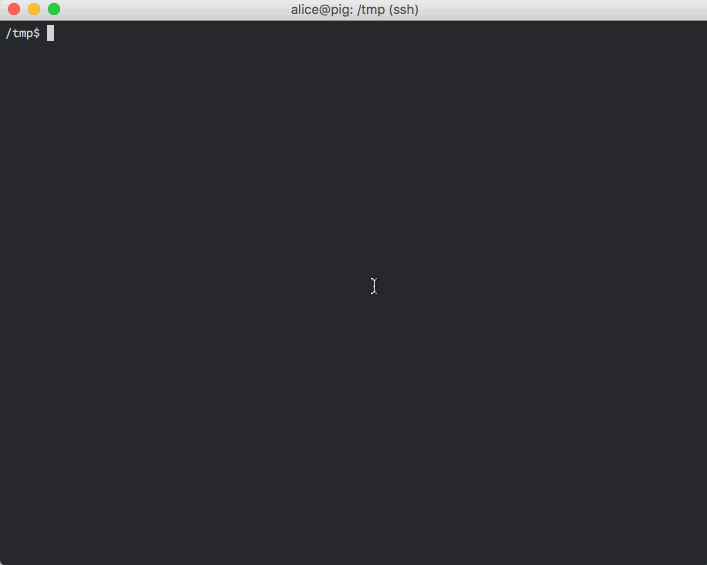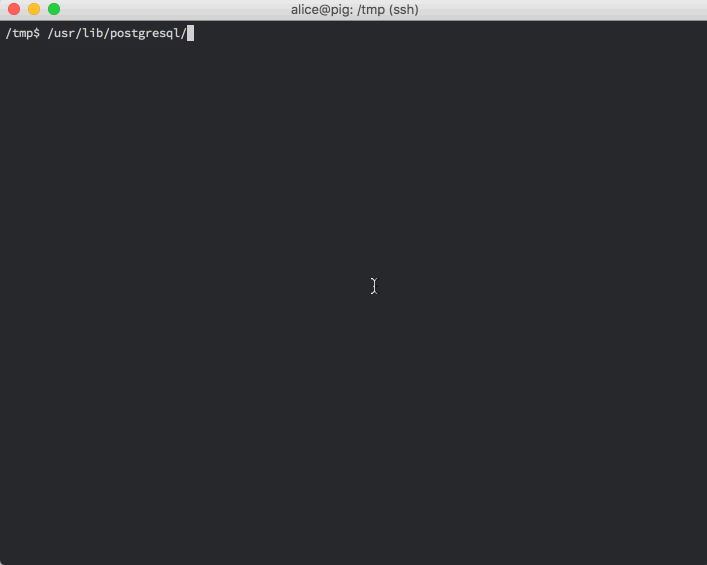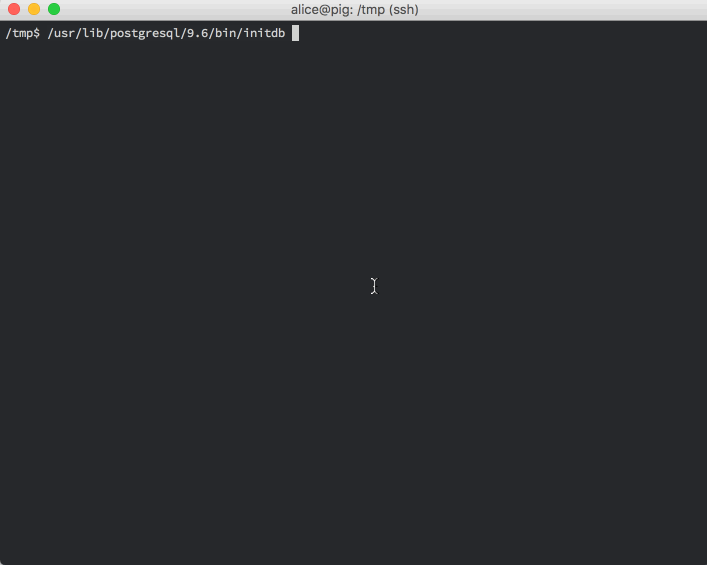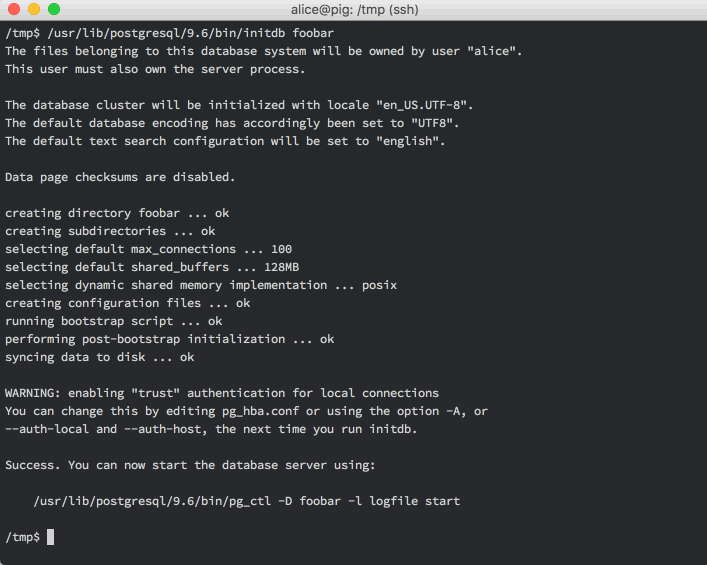
The user who executes this command becomes the “superuser” for that cluster. All the files and directories are owned by this user. In the default installation, the dedicated user postgres serves this purpose.
Configuring your cluster
The file postgresql.conf under the data directory provides the configuration
for this cluster.
There are a couple of things you might want to tweak here:
#port = 5432
#unix_socket_directories = '/var/run/postgresql'The port 5432 would already be in use if this machine is running the standard PostgreSQL daemon. Let’s change this to 5454.
The default Unix socket directory /var/run/postgresql is off-limits to regular
users. You’ll need to change this to some directory for which you have write
permissions. Let’s use /home/alice.
port = 5454
unix_socket_directories = '/home/alice'You can of course, set all the usual options here. You can also find
pg_hba.conf here, and edit it as you need. However, the two changes above are
all you need to start a PostgreSQL server process for the cluster.
Starting the server
With this minimal change in place, let’s bring up a postgres server so we can start using this cluster:
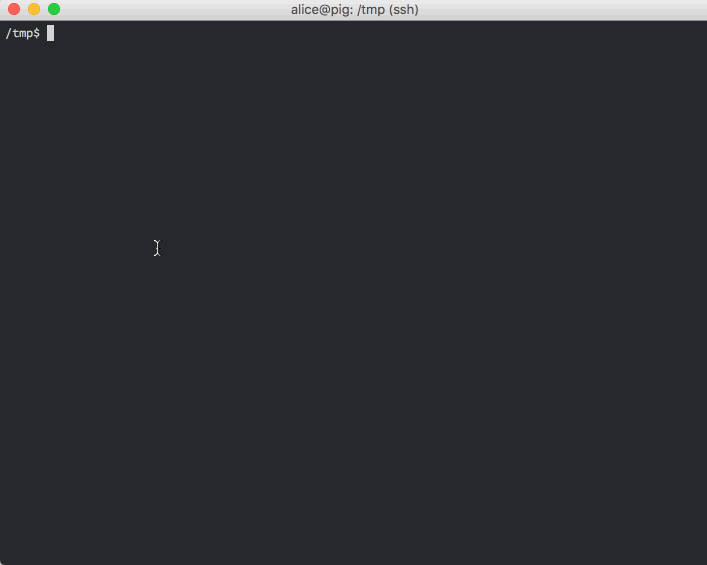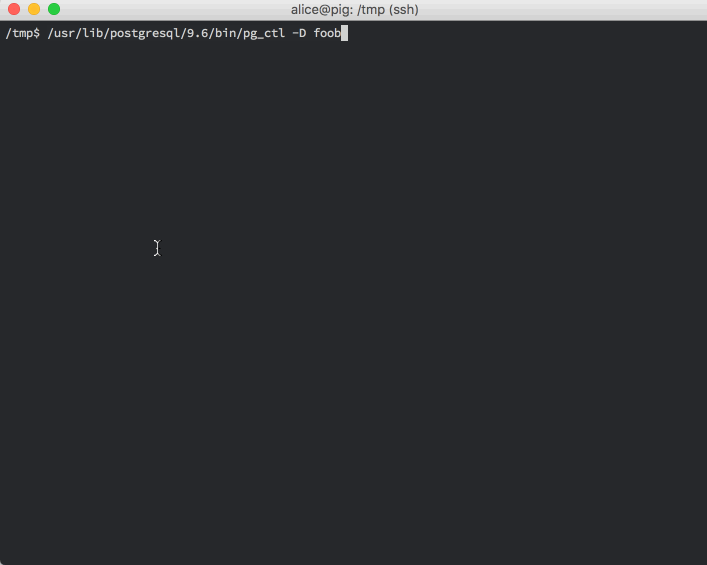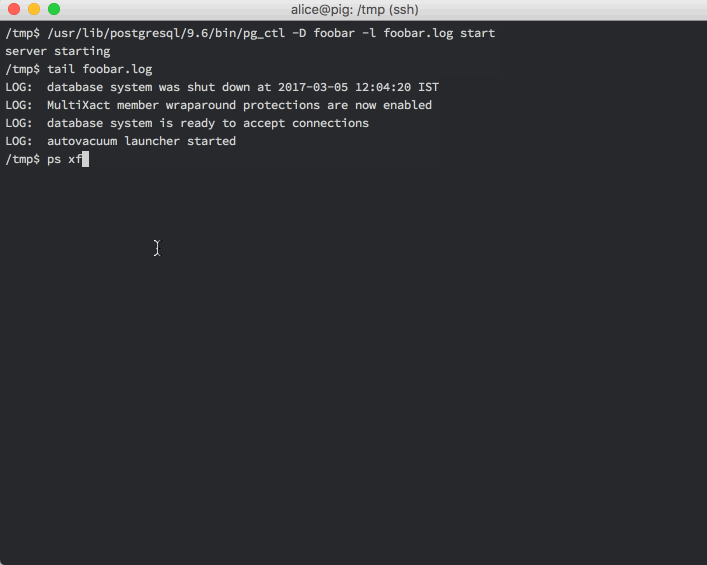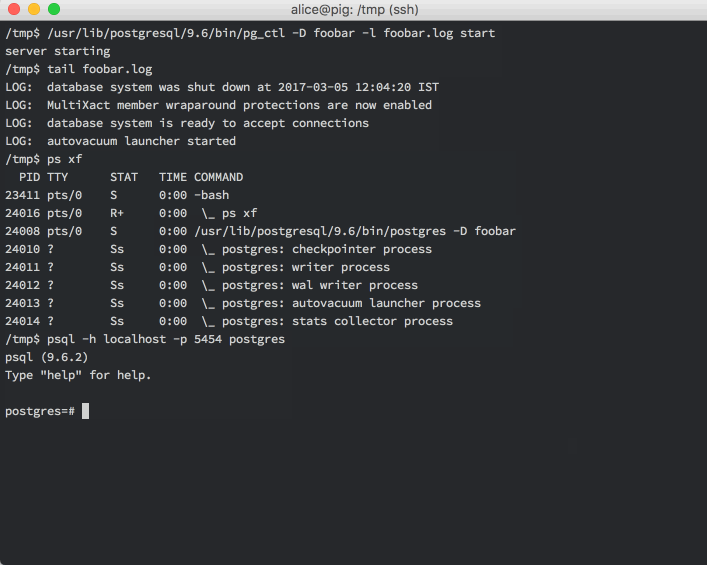
And that’s it! You now have a full-fledged running PostgreSQL server instance.
You can connect to it from any client application, like psql in the screencast
above, and create and manage databases, tables and the like.
You can also see above that the main postgres process has spawned a number of child process that handle housekeeping tasks like checkpointing, vacuuming etc.
Cheatsheet
Here is a cheat sheet of commands you can use to manipulate clusters:
# create a new cluster
/usr/lib/postgresql/9.6/bin/initdb /path/to/db
# start a server for a cluster
/usr/lib/postgresql/9.6/bin/pg_ctl -D /path/to/db -l /path/to/log/file start
# stop the server for a cluster
/usr/lib/postgresql/9.6/bin/pg_ctl -D /path/to/db -l /path/to/log/file stop
# you can also reload or restart the server
/usr/lib/postgresql/9.6/bin/pg_ctl -D /path/to/db reloadAnd here are a list of things that become easy to do if you use clusters:
- automated tests – Create a cluster and start a server as part of your test fixture setup. Run your tests against these, and later stop the server and delete the data directory.
- multiple Postgres versions – You only need the binaries for any version of Postgres to bring up a server of that version. Easily test your app against multiple Postgres versions.
- temporary databases – Create a new cluster rather than a temporary database, and you don’t have to disturb your existing PostgreSQL setup. Especially if the main cluster is replicated.
- embedding Postgres – You can actually include Postgres inside your product this way.
Did you want an actual cluster?
PostgreSQL can be clustered in the “cluster-of-servers” way too.
- You can setup topologies like master-slave or master with multiple slaves using streaming replication. This is built into PostgreSQL.
- For an overview of other options, including multi-master and bi-directional replication, check out this wiki page.
- For clustering with distributed transactions, check out Postgres-XL.
Monitoring PostgreSQL servers
With OpsDash, you can quickly start monitoring your PostgreSQL servers, and get instant insight into key performance and health metrics including WAL archiving and streaming replication.
Additionally, each OpsDash Smart Agent includes the industry-standard statsd interface (and even a graphite interface) to easily report custom metrics.
New Here?
OpsDash is a server monitoring, service monitoring, and database monitoring solution for monitoring MySQL, PostgreSQL, MongoDB, memcache, Redis, Apache, Nginx, HTTP URLs, Elasticsearch and more. It provides intelligent, customizable dashboards and spam-free alerting via email, HipChat, Slack, PagerDuty and PushBullet.