Your PostgreSQL server comes with the ability to replicate it’s data across the network. This replication can be done in various ways, to suit different needs. Read on to learn more about the hows and whys of PostgreSQL replication configurations.
Master-Slave
A 2-server master-slave topology is obviously the simplest replication configuration. In PostgreSQL terms, the master is usually called a primary, and the slave, a standby.
+--------------+ +--------------+
| | | |
| | SR | |
| Primary |+----------->| Standby |
| | | |
| R+W | | no connects |
+--------------+ +--------------+This setup can be achieved via streaming replication – here is an article giving the exact steps needed to set this up. The “SR” in the diagram above denotes “streaming replication”.
We’ve marked the primary as “read and write”, and the standby as “no reads and no writes”. This is the default configuration for a standby. This means that clients will be able to connect to the primary and do both read-only and read-write transactions, but won’t be able to connect to the standby.
The standby is, well, a standby, and if the primary goes down, you can automatically or manually promote the standby to a primary. The clients will have to be instructed to (re)connect to this new primary.
Can we make the standby more useful though?
Hot Standby
It’s easy enough to make the standby into a hot standby. Hot standbys allow clients to connect, and perform read-only transactions. Transactions that attempt to modify data will fail.
To do this set hot_standby to on in the postgresql.conf for the standby.
Read more here.
+--------------+ +--------------+
| | | |
| | SR | |
| Primary |+----------->| Hot Standby |
| | | |
| R+W | | R, no W |
+--------------+ +--------------+This is nice, because in addition to being ready to be promoted as a primary, the hot standbys can also be used to run reports, analytics etc. In other words, the hot standby is a read replica.
But you need to watch out for one thing though.
Eventual Consistency
Consider a client that performs a write transaction on the primary, involving transferring money from one account to another. Another transaction, a read-only one, runs on the read replica, querying the account balance and displaying to another.
All good? Well, not if you look at your account just after transferring money into it and find that the balance hasn’t gone up. Oops.
The write transactions at the primary take a while (exactly how long totally depends on your configuration and load) to get replicated and applied into the hot standby. This means that a client querying the read replica will see an earlier – but still consistent – view of the data than the primary.
In some cases, like nightly-run reports or lengthy analytics queries, this is probably acceptable. In other cases, like this one, not quite so. To avoid this, we need to run such queries on the primary and not the standby – which brings us back to the first configuration.
Or does it?
Synchronized Standbys
Changes to the data managed by your PostgreSQL server happen only within transactions. The server basically reads data into memory and modifies it during the transaction. Just after the transaction ends, the modified data is still in memory, and the server has a few options:
- finish the transaction, let a background thread write out the data to this disk
- wait until the data is written to the disk, then finish the transaction
- write the data to the disk, then send the data to a standby, wait until the standby receives and applies the changes (leaving it in the standby’s memory), then finish the transaction
- write the data to the disk, send it to the standby, wait until the standby has written the modified data out to it’s disk, then finish the transaction
You can actually configure your PostgreSQL server to take any of these actions. And that’s pretty cool, as these things go. Here’s how you can make the settings for each of the options above:
- set
synchronous_commit = off. Don’t use unless you’re sure that this is what you want, though. - set
synchronous_commit = on. This is actually the default. - set
synchronous_commit = remote_applyandsynchronous_standby_names = "*" - set
synchronous_commit = remote_writeandsynchronous_standby_names = "*"
(For more information regarding the configuration, read the docs about synchronous replication, the synchronous_standby_names option and the synchronous_commit option.)
By default, the streaming replication process that we covered so far, is asynchronous. If you use “remote_apply” or “remote_write”, this streaming replication becomes synchronous. When you use synchronous replication to send changes to a standby, that standby is called a synchronous standby.
+--------------+ +--------------+
| | | |
| | Sync. | Synchronized |
| Primary |+----------->| Hot Standby |
| | SR | |
| R+W | | R, no W |
+--------------+ +--------------+The synchronous replication comes at the cost of increased transaction time, but both servers will present the same point-in-time view of data to clients.
It is still read-only, though. Can we allow writes to it as well?
Logical Replication
If writes were allowed at both servers, it would form a “multi-master” configuration. Although stock PostgreSQL does not support multi-master configurations, it does have a feature called logical replication, available since version 10.
+--------------+ +--------------+
| | LR | |
| |+----------->| |
| Primary | | Primary |
| | LR | |
| R+W |<-----------+| R+W |
+--------------+ +--------------+Logical replication lets you push changes from selected tables to other servers. There is no restriction that the receiving server be read-only.
You can read more about it in this blog post and in the docs.
Logical replication does not provide true multi-master features, like Galera or Group Replication do in the MySQL-Percona-MariaDB world. Indeed, it is more of a tool in your toolchest that can be applied in certain use cases. If you really need multi-master replication in PostgreSQL, start here.
One Primary and Two Standbys
Let’s have a look at topologies with three servers. Here is one with a primary and two read replicas:
+-------------+ +-------------+ +-------------+
| | | | | |
| | SR | | SR | |
| Hot Standby |<-------------+| Primary |+----------->| Hot Standby |
| | | | | |
| R, no W | | R+W | | R, no W |
+-------------+ +-------------+ +-------------+It works as you’d expect, with the data sent from the primary to both the standbys at the same time. There is no guarantee that both the standbys present identical views of the data.
You can also have synchronous replication between the standbys instead:
+-------------+ +-------------+ +-------------+
| | | | | |
| Synchronized| Sync. | | Sync. | Synchronized|
| Hot Standby |<-------------+| Primary |+----------->| Hot Standby |
| | SR | | SR | |
| R, no W | | R+W | | R, no W |
+-------------+ +-------------+ +-------------+With multiple synchronous standbys, you now have more possibilities. Turns out our “synchronous_standby_names” option from before can do more tricks. Once a transaction is ended, the changes can be sent to:
- all standbys
- the first N from a prioritized list of standbys
- any N from a list of standbys
How’s that! Compare that to Cassandra’s write consistency options!
A full discussion of the syntax is out of scope here, but check out the docs for more info.
Finally, it is possible to cascade the replication:
+-------------+ +-------------+ +-------------+
| | | | | |
| | SR | | SR | |
| Primary |+------------->| Hot Standby |+----------->| Hot Standby |
| | | | | |
| R+W | | R, no W | | R, no W |
+-------------+ +-------------+ +-------------+This works because standbys can accept “replication connections” to do streaming replication. Cascaded replication can be used to reduce the load on the primary while still maintaining two standbys. The standbys further away from the primary are called downstream and the other way upstream. Synchronous streaming replication out of a standby is not supported.
Where to go from here
Replication in PosgreSQL represents a whole lot of features, knobs and levers accumulated into a stable codebase over more than a decade. Understandably, it takes a lot of reading and experimenting to get to any level of comfort with it.
Start at the top here, and keep going!
Monitoring PostgreSQL With OpsDash
With our own product, OpsDash, you can quickly start monitoring your PostgreSQL servers, and get instant insight into key performance and health metrics including replication stats.
Here’s a default, pre-configured dashboard for PostgreSQL.
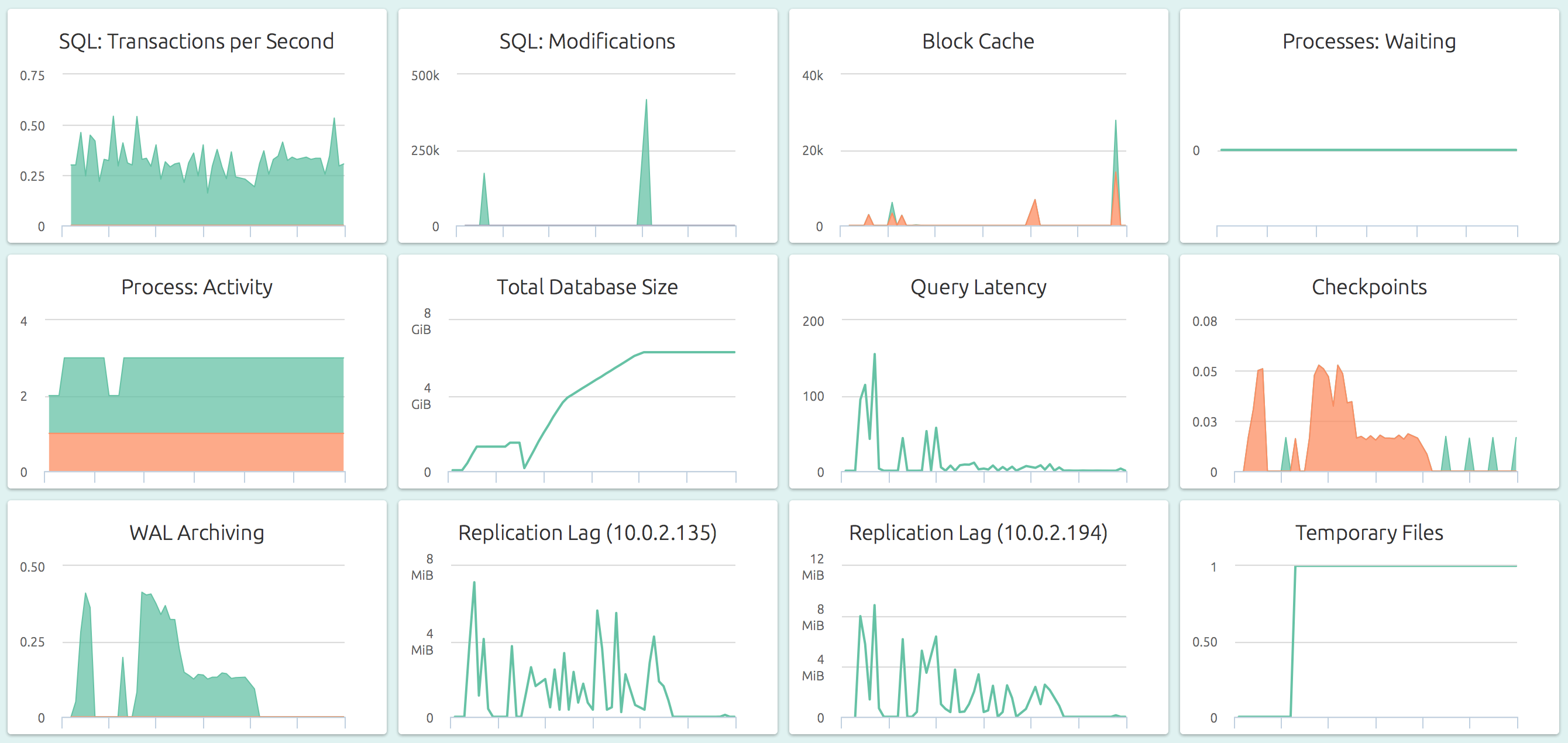
OpsDash strives to save you the tedious work of setting up a useful dashboard. The metrics you see here were carefully chosen to represent the most relevant health and performance indicators for a typical PostgreSQL instance.
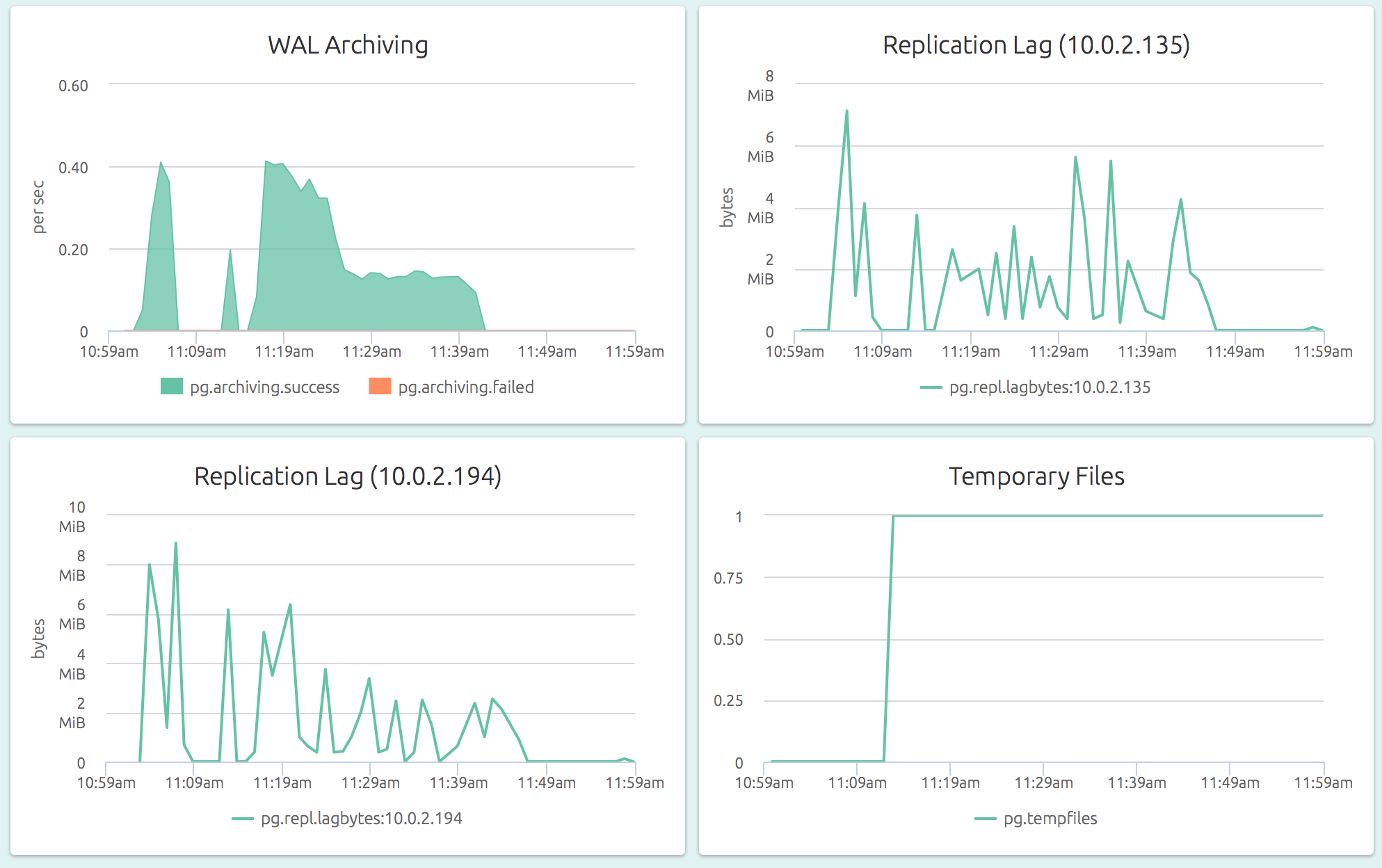
OpsDash understands the streaming replication feature of PostgreSQL and displays per-slave replication status on the master:
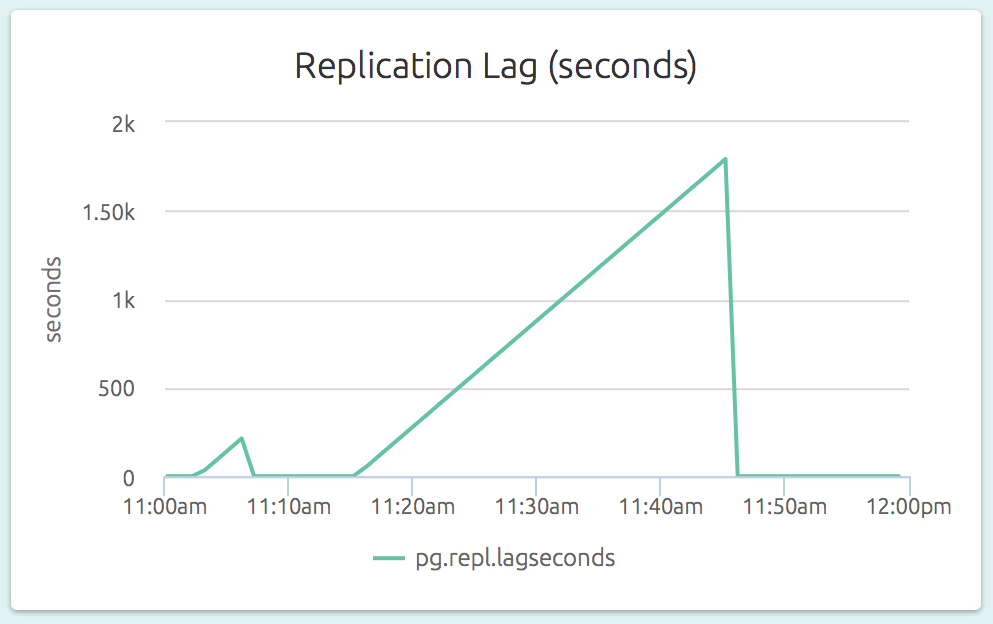
The replication lag (as a length of time) is also visible on a slave’s dashboard. In the graph below (part of the dashboard of a slave), we can see that the slave could not catch up to the master’s changes for a while.
Sign up for a free 14-day trial of OpsDash SaaS today!