PostgreSQL comes with the tools you need to perform backups, incremental/continuous backups, and do point-in-time-recovery from backups. Archiving WAL files is a fundamental operation that facilitates these features. Read on to learn more about what it is all about.
What is a WAL, anyway?
WAL is short for Write Ahead Log.
WALs are used in nearly all modern RDBMS systems to provide durable and atomic transactions. Simply put, any transaction performed on the database is first written out as a WAL file, then applied to the actual on-disk table data files. WAL files are strictly sequential. This makes the WAL file sequence a “replay log” of changes.
The concept is similar to Redis’ AOF, MySQL’s binlog and MongoDB’s oplog.
So are they actual files? Yes. They live in $PGDATA/pg_xlog, where
$PGDATA is the data directory, like /var/lib/postgresql/9.6/main. They are
binary files, 16MB each.
Won’t they keep piling up? They will, if you don’t tell Postgres when to
clean up. You can limit these files by number (wal_keep_segments) and/or
total size (max_wal_size).
Archiving WALs
As you keep modifying the data in the databases on a server, WAL files keep getting generated (and discarded after a while).
If you save a copy of each WAL file that was generated, you could replay back the entire set of changes into another server. Doing this in real-time is better known as replication. You can read more about PostgreSQL replication here.
Saving all generated WAL files to a safe offline location essentially becomes incremental backup.
[Side note: Technically, there is one sequence of WAL files for single instance of a running PostgreSQL server. The WAL files would contain all the changes across all the databases managed by that instance.]
In PostgreSQL terms, copying out generated WAL files is called archiving, and getting the server to read in a WAL file and apply it is called restoring.
The Archive Command
Since PostgreSQL does not know how you’d like to archive the WAL files, you’ve to supply a script. PostgreSQL will invoke this script as and when each WAL file is ready for archiving. The script has to process it (typically copy it to a safe location) and report whether it was successful, via the exit code (that is, exit 0 from your script on successful completion).
Once the script has successfully processed a WAL file, the server is free to delete or recycle it when it sees fit.
The script is set using the archive_command configuration setting.
(docs).
Here are some examples:
# Copy the file to a safe location (like a mounted NFS volume)
archive_command = 'cp %p /mnt/nfs/%f'
# Not overwriting files is a good practice
archive_command = 'test ! -f /mnt/nfs/%f && cp %p /mnt/nfs/%f'
# Copy to S3 bucket
archive_command = 's3cmd put %p s3://BUCKET/path/%f'
# Copy to Google Cloud bucket
archive_command = 'gsutil cp %p gs://BUCKET/path/%f'
# An external script
archive_command = '/opt/scripts/archive_wal %p'While writing your own script, keep in mind a few things:
- If the script fails, it will be invoked again, repeatedly, until it succeeds. There are no delays between retries or stop-after-N-retries features.
- Files are 16MB in size, and usually compress well.
- The script will be called sequentially, there is no parallelism.
- It’s a best practice not to overwrite destination files if they exist.
- You should treat the file that PostgreSQL passes you as read-only. If you want to compress it, be sure not to modify the original.
- The script will be invoked as the user
postgres. Ensure that this user has the necessary read/write permissions for relevant directories.
The WAL level
By default, WAL files contain only the information needed
to recover from a crash or immediate shutdown. This is the minimal WAL level.
The next level is archive (or replica in version 9.6 and above). Setting the
WAL level to archive or above gets the server to include enough information to
allow the archival (and restoration) of WAL files.
The level after that is called hot_standy (also mapped to replica in
version 9.6 and above), and includes information required to run read-only
queries on a standby server.
With the last level logical, it is possible to extract logical change sets
from WAL.
The WAL level is a configuration setting, called wal_level. For our needs,
we need set to set this to at least archive. PostgreSQL will refuse to start
if you request archiving but wal_level is less than this.
# The WAL level must be archive or higher.
wal_level = archiveArchive Timeout
If your PostgreSQL server is having a peaceful day with a low transaction rate, it may take a while to fill out one complete WAL file. From an operations perspective, though, it is usually a good idea to have at least one WAL file backed up every X minutes (or hours or days, according to your setup).
The setting archive_timeout can be used to tell PostgreSQL to generate at
least one WAL file every “archive_timeout” duration, even if it is empty.
# Ensure there is at least one WAL file for each "archive_timeout" duration.
archive_timeout = 1hControlling the WAL files
PostgreSQL offers a few levers to control the number of WAL files that lie
around in the pg_xlog directory.
The settings min_wal_size and max_wal_size place limits on the the total
size of the WAL files. Having a minimum limit allows recycling of old files
(they are renamed first). The upper limit is a soft limit, because the server
can safely delete only those files which have been successfully archived.
The wal_keep_segments can be used to set a minimum limit for the number of
WAL files in pg_xlog. This is mainly to allow for slow or intermittent standby
servers.
# This is a soft upper limit on the total size of WAL files.
max_wal_size = 1GB
# Keep around at least these many WAL files (aka segments).
wal_keep_segments = 10The Archival Settings
Finally, there is the archive_mode setting, which obviously must be set to
on for archiving to work. Here are the important settings for archival,
rounded up:
# The WAL level must be archive or higher.
wal_level = archive
# This is a soft upper limit on the total size of WAL files.
max_wal_size = 1GB
# Keep around at least these many WAL files (aka segments).
wal_keep_segments = 10
# The archive_mode must be set to on for archiving to happen.
archive_mode = on
# This is the command to invoke for each WAL file to be archived.
archive_command = '/opt/scripts/archive_wal %p'
# Ensure there is at least one WAL file for each "archive_timeout" duration.
archive_timeout = 1hRestoring WALs
Restoring WALs is usually done in the context of restoring from a backup, doing a point-in-time recovery (PITR) or streaming replication. It is a bit too extensive to cover in this same blog post, so we’ll just have to do this as another post – stay tuned!
You can read about streaming replication in our other blog post called “All About PostgreSQL Streaming Replication”.
Monitoring WAL Archiving
PostgreSQL provides a statistics collector that can be queried to examine the
state of WAL archiving. Specifically you can use the pg_stat_archiver
to see the WAL success and failure counts.
With OpsDash, you can quickly start monitoring your PostgreSQL servers, and get instant insight into key performance and health metrics including WAL archiving.
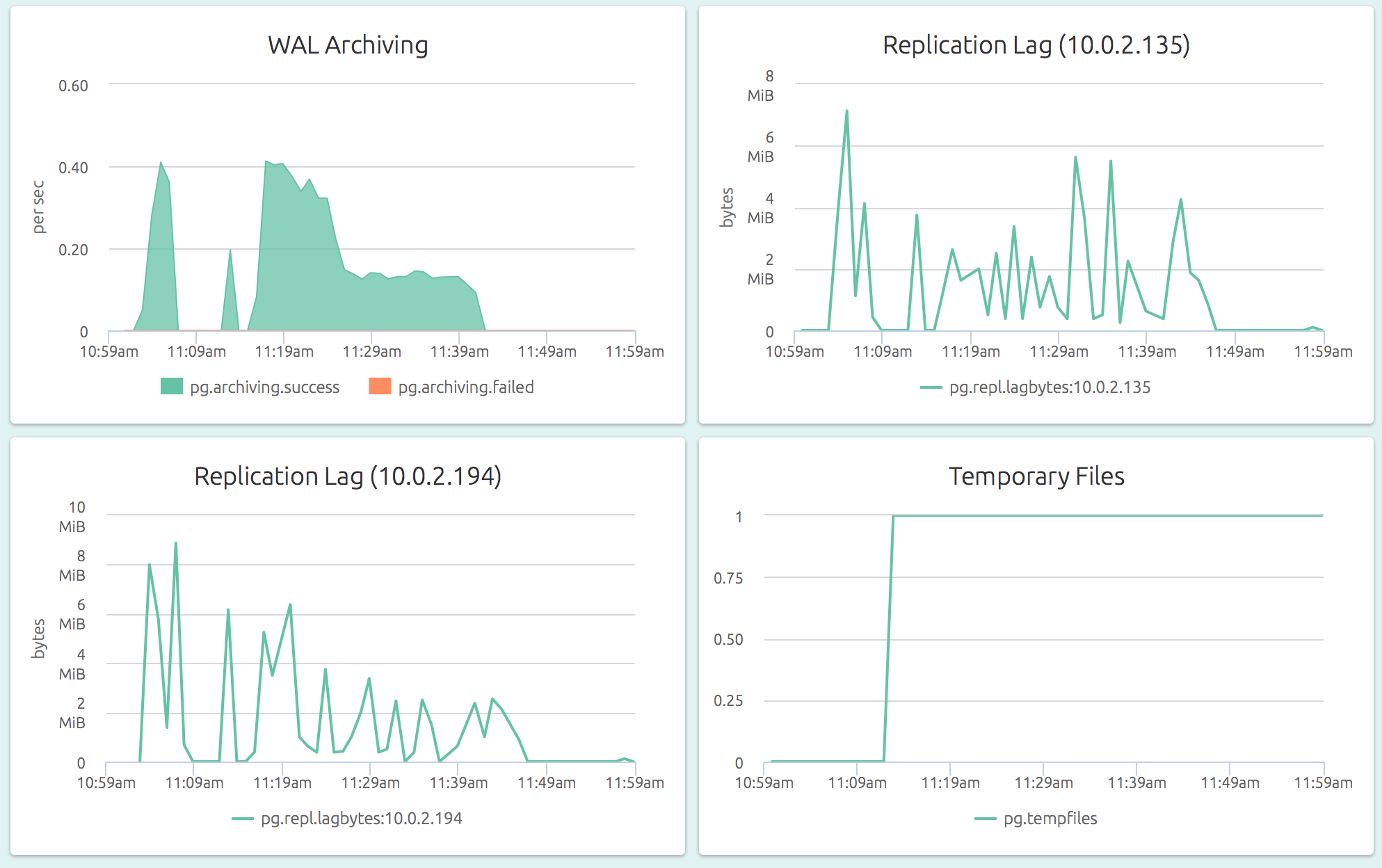
Adding a threshold-based alert to the archive failure count metric is a quick and easy way to catch a failing archival job before it gets out of control and WAL files eat away your server disk space.
More on PostgreSQL
- Using PostgreSQL Full Text Search With Golang
- All About PostgreSQL Streaming Replication
- PostgreSQL Monitoring with OpsDash
New Here?
OpsDash is a server monitoring, service monitoring, and database monitoring solution for monitoring MySQL, PostgreSQL, MongoDB, memcache, Redis, Apache, Nginx, HTTP URLs, Elasticsearch and more. It provides intelligent, customizable dashboards and spam-free alerting via email, HipChat, Slack, PagerDuty and PushBullet.
OpsDash is available as a self-hosted, on-premise solution and as a SaaS solution. Choose what’s right for you!
Interested in self-hosted? Start Free today!
Prefer SaaS? Signup for the beta!