PostgreSQL provides different ways to backup and restore your databases. With PostgreSQL, backups can be full, incremental or continuous, and they can be at logical or filesystem level. Point-in-time recovery is possible from incremental backups. PostgreSQL even supports a feature called timelines, which is a sort of branching history of your backup and restores.
Let’s have a look at the common options for backup and restore.
Dumping Using pg_dump and pg_dumpall
The pg_dump utility can be used to generate a logical dump of a single
database. If you need to include global objects (like uses and tablespaces) or
dump multiple databases, use pg_dumpall instead.
The output generated by pg_dump is not a traditional “backup”. It omits
some information that makes it unusable for some operations, like for example
initializing a standby server. The output is also much bigger than from other
backup methods, making it suitable only for “small” databases.
It is however, powerful in other aspects:
- You can connect as a normal user that has read-only privileges for all the relevant objects
- You can selectively restore objects from the dump (using custom format)
- You can manually edit and tweak SQL before restore (using SQL format)
pg_dump can create dumps as plain SQL files, as a tar archive, as a directory
with a set of files or as a single file called a custom format file. Of these,
the SQL file and the custom format file are the most interesting.
pg_dump is invoked like this:
# dump to single SQL file
$ pg_dump -d mydb -n public -f mydb.sql
# dump to a custom format file
$ pg_dump -d mydb -n public --format=custom -f mydb.pgdmpNote that we’re dumping only objects from the public schema. This is typically
what you want.
The file mydb.sql is a plain text file with PostgreSQL commands, and the file mydb.pgdmp is a custom format file. Note that the custom format file is gzip-compressed and it is not required to compress it again.
The PostgreSQL docs have more info about all the options for pg_dump and pg_dumpall.
Restoring from a SQL dump file
The SQL file of course, can be sourced in the usual way with psql to recreate
the database(s). However, there are a few options that you probably want to
specify so that the execution goes through cleanly – see the second example
below. Of these, the -1 option ensures that the whole script is executed in
a single transaction, so that you have a all-or-nothing restore.
# restoring from a SQL dump file, the simple version
$ psql -d mydb_new < mydb.sql
# restoring from a SQL dump file, the recommended version
$ PGOPTIONS='--client-min-messages=warning' psql -X -q -1 -v ON_ERROR_STOP=1 --pset pager=off -d mydb_new -f mydb.sql -L restore.logRead about all the psql options here.
Restoring from custom format dump files
Let’s say someone accidently dropped a table, and you’d like to restore only that table. Restoring from a custom format pg_dump file is the easiest way to do this.
You can use the pg_restore utility to restore a full custom format dump file,
but it’s real value lies in the ease of importing a single function, table or
trigger from the dump file.
# restoring from a dump written to a custom format file
$ pg_restore -d mydb_new -v -1 mydb.pgdmp
# restore a single table from the dump
$ pg_restore -d mydb_new --table=mytable -v -1 mydb.pgdmp
# restore a single function from the dump
$ pg_restore -d mydb_new --function=myfunc -v -1 mydb.pgdmpYou can read more about pg_restore here.
Backup Using pg_basebackup
The tool pg_basebackup is the standard way to take full, filesystem-level
backup of a PostgreSQL database cluster. (Here cluster refers to the Postgres’
usage of the term, that is, all the databases managed by a single server
process.)
The pg_basebackup makes a replication protocol connection (just like a
replication client) to the PostgreSQL server, and creates a binary copy of the
data files that live in the $PGDATA directory of the server. The copy it
creates is consistent – the files exactly correspond to the state at the end of
some particular transaction.
This also implies that pg_basebackup needs to connect as a user who is
explicitly permitted to use the replication protocol. You can do this by adding
lines to pg_hba.conf similar to:
# TYPE DATABASE USER ADDRESS METHOD
local replication myuser peer
host replication myuser 10.0.0.1/32 md5If you are worried about missing transactions that happen while the backup is
going on, you can ask pg_basebackup to fetch and include those transaction log
files (WAL files) also, using the -x or -X options.
# create the backup as a standard Postgres files in /path/to/datadir
$ pg_basebackup -D /path/to/datadir
# create a backup tar.gz file for each tablespace under /path/to/dir
$ pg_basebackup --format=tar -z -D /path/to/dir -P
# also include transactions since the backup started
$ pg_basebackup -x -D /path/to/datadirThe pg_basebackup docs has more details.
Restoring from pg_basebackup files
The files created by pg_basebackup is an exact, consistent mirror of the
files under $PGDATA (this is typically like /var/lib/postgresql/9.6/main).
Restoring involves only moving these files into the appopriate place, like this:
$ sudo systemctl stop postgresql
$ sudo rm -rf /var/lib/postgresql/9.6/main/*
$ sudo -u postgres tar -xvC /var/lib/postgresql/9.6/main -f /path/to/dumpdir/base.tar.gz
$ sudo systemctl start postgresqlStreaming Replication
If you can afford the extra resources, having an up-to-date hot standby server, continuously replicating from your primary server, is a great way to mitigate downtime risk. You also get a “free” server to run your reports and other analytics, without loading your primary.
Learn how you can use the streaming replication feature to do this in our All About PostgreSQL Streaming Replication blog post.
Note that it is possible to take backups of any type from standby servers also.
Incremental and Continuous Backup
A PostgreSQL server generates a stream of changelog files, called WAL (Write Ahead Log) files. By archiving these files as they are generated, you can create an incremental, continuous backup system.
You can read more about WAL archiving in this All about WAL archiving in PostgreSQL blog post.
Typically, full backups are taken periodically along with continuous WAL archiving. Together, these allow for point-in-time recovery.
Point-in-time Recovery (PITR)
PITR refers to restoring the PostgreSQL cluster to the state it was at a particular point in time.
For example, let’s say something drastic happened at 11:20 AM and you’d like to restore the databases to the state it was just before 11:20. Assume you take daily backups at 01:00 AM each day and use continuous WAL archiving, you can follow these steps:
- stop postgres
- restore the last full backup, the one made at 01:00 AM
- mount the filesystem with the WAL archive files
- create a
$PGDATA/recovery.conffile that has the contents:
restore_command = 'cp /path/to/archive/%f "%p"'
recovery_target_time = '2017-02-08 11:20:00 UTC'
recovery_target_inclusive = falseThen start the Postgres server. On startup, it will repeatedly invoke the
restore_command script to fetch WAL files from 01:00 AM, upto but not
including 11:20 AM. At that point, it ends the recovery phase and starts normal
operations.
You can read more about PITR in the PostgreSQL docs.
Monitoring Backups
It is not sufficient to just add cron jobs for backup, you need to monitor them too!
Be sure to monitor:
- whether your backup jobs are completing successfully
- the time taken for each backup, and keep an eye on how this goes up
Additionally, you should also have another cron job that picks up a recent backup and tries to restore it into an empty database, and then deletes the database. This ensures that your backups are accessible and usable. Make sure you try restoring against the right versions of your PostgreSQL server.
You should monitor this restoration cron job too, as well as the time taken for the restoration. The restoration time has a direct impact on how long it’ll be before you are back online after a database crash!
Monitoring Backups, WAL Archiving and Replication
With OpsDash, you can quickly start monitoring your PostgreSQL servers, and get instant insight into key performance and health metrics including WAL archiving and streaming replication.
Additionally, each OpsDash Smart Agent includes the industry-standard statsd interface (and even a graphite interface) to easily report custom metrics.
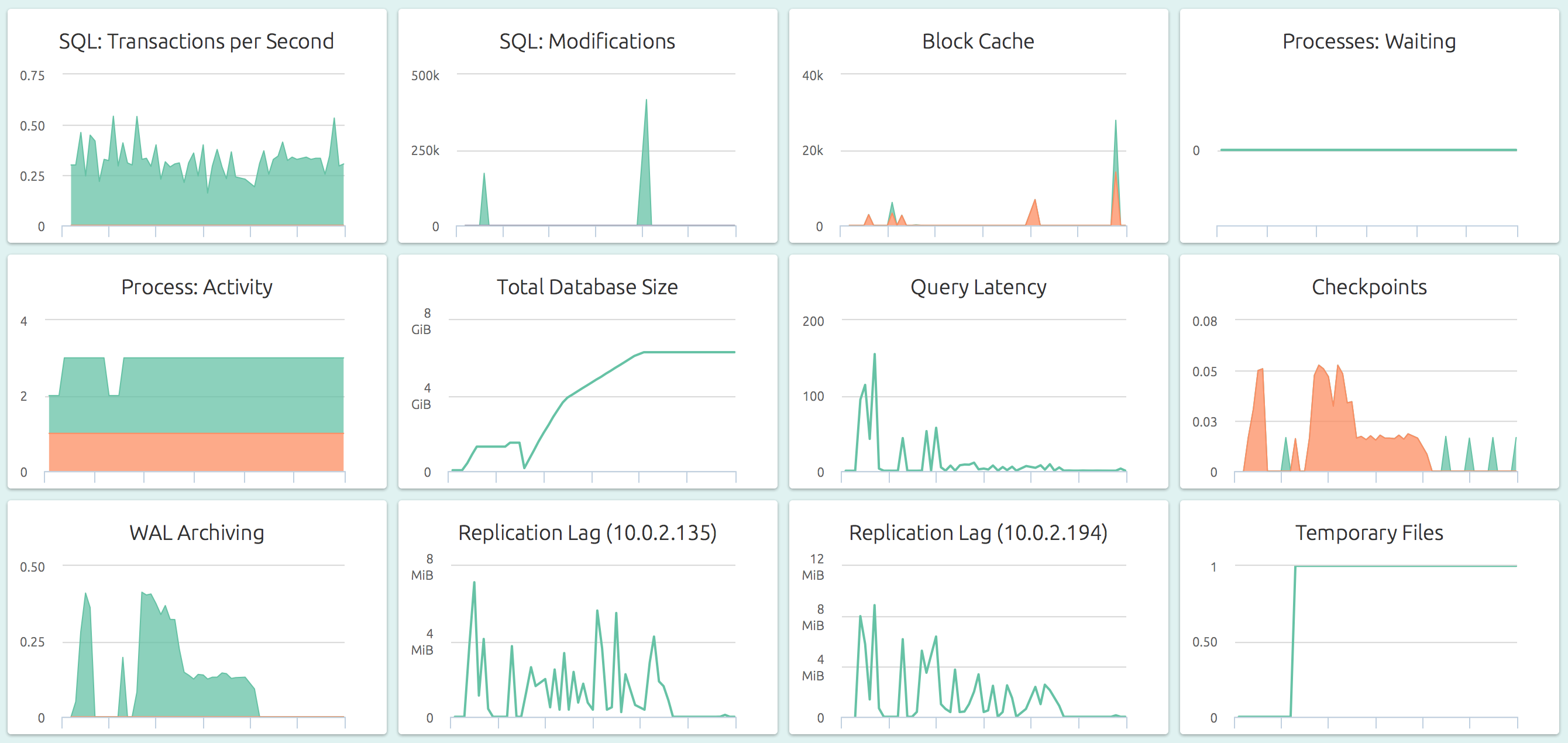
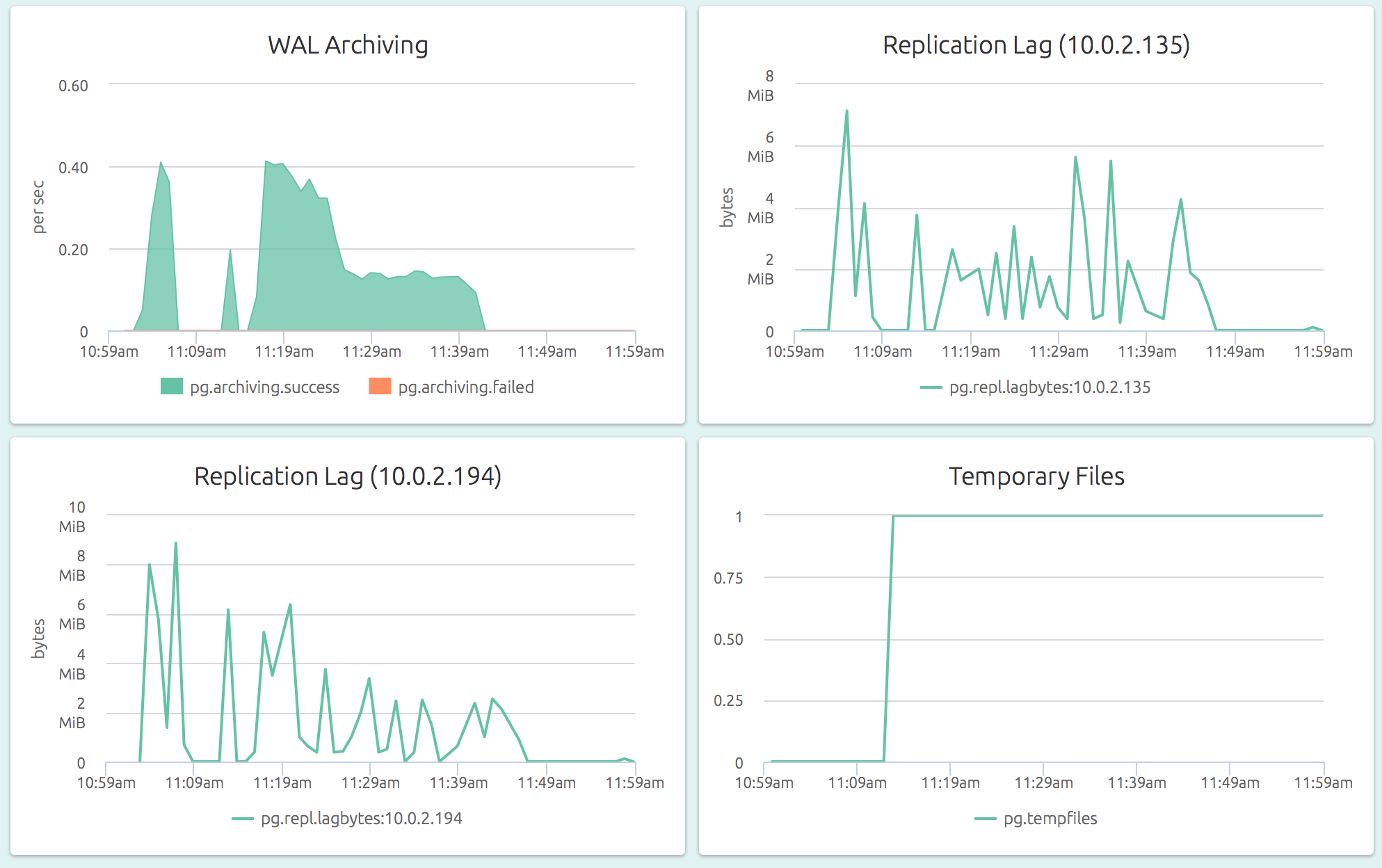
The dashboard below shows the streaming replication lag and WAL archiving status for a server:
New Here?
OpsDash is a server monitoring, service monitoring, and database monitoring solution for monitoring MySQL, PostgreSQL, MongoDB, memcache, Redis, Apache, Nginx, HTTP URLs, Elasticsearch and more. It provides intelligent, customizable dashboards and spam-free alerting via email, HipChat, Slack, PagerDuty and PushBullet.